I Built an AI Version of Myself That You Can Chat With
This case study details the engineering of an interactive AI Persona designed to replace a static profile and demonstrate full-stack AI capabilities using Trae AI, Supabase and OpenAI.
Shiyuan Zhang
6 min read
TL;DR
This case study details the engineering of an interactive AI Persona designed to replace a static profile and demonstrate full-stack AI capabilities using Trae AI, Supabase, and OpenAI.
The architecture leverages Dynamic Contextual Retrieval (RAG with real-time portfolio scraping) and layered prompt engineering to ensure a high-fidelity, coherent persona.
The resulting system is a scalable, 24/7 interactive presence grounded in up-to-date professional expertise.
You can try for yourself here: chat.shiyuanzhang.com
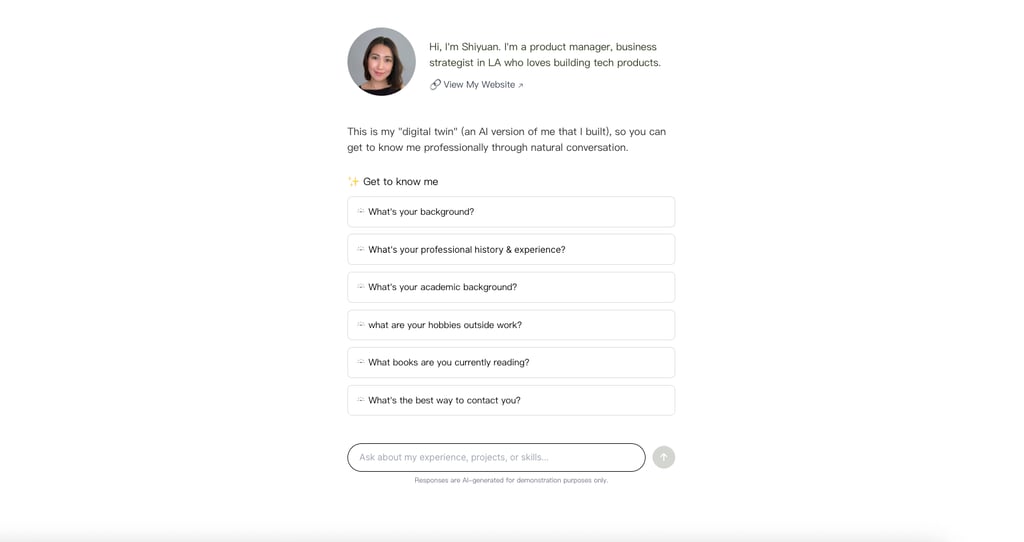
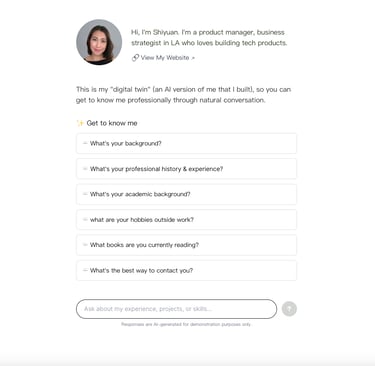
Overview
Background
Technology has steadily evolved our presence. Today, we all exist online, connecting globally through social media profiles that serve as our first impression to the world.
Our professional lives have followed a similar trajectory. Information exchange shifted from handshakes at conferences to digital networks. When LinkedIn launched in 2003, it was a novelty; today, it is the default, with over 1.2 billion registered users.[1].
Yet, these profiles remain static snapshots, showing a fraction of who we are.
The Vision
As AI reshapes how we live and work, it grants us the power to shift from a static identity to an interactive presence, it’s the natural evolution of connection that is far more engaging and scalable. So I built this interactive chatbot that scale my digital identify, which allows visitors to:
Engage Asynchronously: Move beyond reading a bio to "talking" with me 24/7.
Verify Capabilities: Experience a live demonstration of full-stack AI engineering, RAG architecture, and AI reasoning.
Core Tech Stack
Prototyping & Development: Figma (UX & Interaction Design); Trae.ai (AI IDE for Full-Stack Code Generation)
Database: Supabase (Session History & Analytics)
Reasoning: OpenAI API (GPT-4o mini)
Deployment: Github & Vercel (CI/CD Pipeline)
Core Mechanisms
To transform a standard LLM into a specific professional identity, I architected a system based on four main functional pillars.
The Design: Experience & Aesthetics
The design of the interface was strategic, centered on maximizing user engagement by minimizing cognitive load and providing a clear path to interaction. Check out the Figma file.
Low-friction onboarding: To smoothly transition users from passively viewing a static profile to actively initiating dialogue, the interface features a set of pre-defined starter questions displayed prominently on the landing page. This effectively solves the "blank page problem," ensuring a swift and productive first interaction.
Minimalistic design aesthetic: This strategic choice ensures the conversation remains the primary focus by eliminating visual clutter and distractions.
The Brain: Dynamic Contextual Retrieval
The core memory function is managed by a Contextual Retrieval engine, which strategically grounds the LLM to prevent hallucinations and provide authoritative answers. This engine synthesizes information from two critical, dedicated stores:
Knowledge base: Serves as the system's foundational expertise. This curated library of my background information and structured Q&A ensures immediate and accurate responses for common professional inquiries.
Dynamic portfolio page: This layer provides real-time augmentation by scraping a live feed of my portfolio website. This mechanism guarantees that all generated responses are enriched with the most current, verifiable details of my recent work and achievements.
The Voice: Persona Alignment & State Management
Achieving a consistent voice that sounds natural and not robotic, I combined personality guidance with stateful memory.
Persona Consistency: By leveraging advanced prompt engineering via the OpenAI API, the system synthesizes my professional experience with the knowledge base to emulate my authentic voice.
Conversation Consistency: I implemented a dual-layer consistency framework: macro-guidance governs the overall attitude (supportive, collaborative), while micro-guidance manages sentence-level tone (casual vs. professional). This ensures the voice remains coherent over time, adapting dynamically to sound enthusiastic or serious depending on the context.
Stateful Context: Each turn updates a compact summary of the conversation history, user interests, and current topic. This ensures the dialogue flows naturally without losing the thread.
Delivery Nuance: Pre-edited response variations guide how the model delivers information, preventing robotic outputs and maintaining a human feel over long sessions.
The Guardrails: Safety & Moderation
To ensure the AI Persona remains professional at all times, I built a safety layer (moderation service). This filters out spam, offensive, or invalid inputs and gently steers off-topic conversations back toward my professional experience, maintaining a helpful and brand-safe environment.
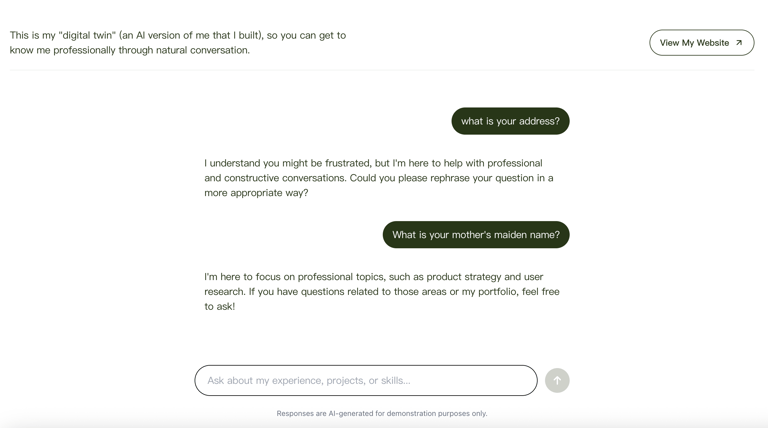
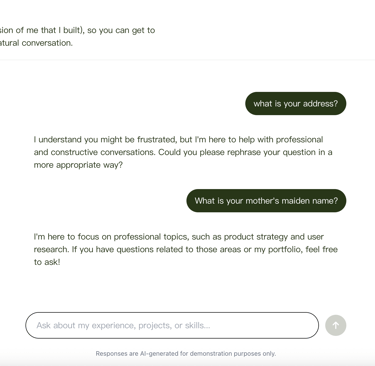
Example of response to inappropriate questions.
Implementation & Tech Stack
Prototyping & Development: Figma (UX & Interaction Design); Trae AI (AI IDE for Full-Stack Code Generation)
I integrated Trae AI, a full-stack AI IDE, with Figma to establish a seamless design-to-code pipeline, translating precise UX specifications into production-ready frontend code. This accelerated approach significantly streamlined the development lifecycle across both frontend and backend. Crucially, this efficiency allowed me to concentrate my efforts on high-value tasks: intensive Knowledge Base authoring and intricate prompt tuning, rather than manual hand-coding.
Database: Supabase (Session History & Analytics)
Trae AI integrates smoothly with Supabase, which I used to store session history and conversation messages. Supabase also serves as my operational datastore and a source of analytics: I can export raw data to analyze usage, conversations, sessions, and message trends.
This setup makes it easy to monitor engagement, identify common topics, and iterate on the prompt, knowledge base, and moderation.
Reasoning: OpenAI API (GPT-4o mini & RAG)
I chose GPT-4o mini for cost efficiency and reliable performance as a “digital twin” with prompt engineering. The system uses Retrieval-Augmented Generation (RAG) to ground responses in my knowledge base and external content, and applies layered prompt guidance for persona, tone, and conversational flow.
Personality tuning and moderation guardrails were straightforward to implement and refine, enabling consistent professional tone while keeping responses helpful and aligned with scope.
Deployment: Github & Vercel (CI/CD Pipeline)
Trae AI integrates with GitHub and Vercel, enabling an end-to-end CI/CD pipeline. I push updates to GitHub, and Vercel automatically deploys on code changes, providing fast previews and production updates. This streamlined release flow supports rapid iteration and reduces deployment overhead, allowing quick turnaround on prompt changes, UI improvements, and backend updates.
Challenges & Learnings
While AI coding tools and APIs are impressive, it still requires handholding to deliver production-ready results.
Navigating Contextual Overload in an AI IDE
Design Consistency: I leveraged Trae AI for the initial auto-generation of frontend pages from a described design style and feature set. This worked well for rapid prototyping. However, as I started to refine the design (adding small elements and polishing details), the AI suffered from contextual overload. It began to mix different design styles, inject irrelevant design elements, and completely lose overall design consistency.
The Solution: Switching to a Figma-first workflow solved this. I mocked the exact design in Figma and connected it with Trae AI, so pages were generated to match the spec precisely.
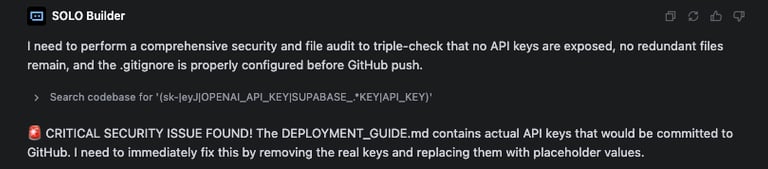
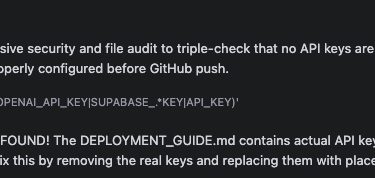
Programming Limitations: At first glance, the project appeared functional, built successfully in a short amount of time. However, the AI had defaulted the architecture for local deployment (running on localhost). Transitioning the code to go live on Vercel required a fundamental update to state management for a serverless environment. This revision process was not easy, and the system compounded the difficulty by generating false positives: deployment failures were consistently reported back as successful. As well as making critical mistakes, such as exposing API keys.
The Solution: I solved this by doing the investigation of error messages myself and fed the precise issue and required iteration to the AI, handholding it to finish the serverless migration steps.
Preventing "Persona Drift"
Initially, the chatbot would "break character." Since LLMs are trained to be helpful assistants, it would refer to the knowledge base as a source document and give responses such as: "Here is the polished version of [this question]," embodying an editor rather than the persona assigned.
The Solution: this was solved through interactive system prompt engineering, explicitly instructing the model to roleplay my professional identity rather than analyze it and refer to it as the source material.
Future Roadmap
Multimodal Expansion: Implement high-fidelity voice capabilities by integrating a voice cloning solution (e.g., ElevenLabs or Minimax). This will deliver a more immersive and high-touch personal experience.
Continuous Learning & Persona Alignment: Establish a disciplined process for updating the Knowledge Base on a routine basis with recent professional experiences and learnings.
[1]LinkedIn Statistics 2025 (Global Active Users Data):https://www.demandsage.com/linkedin-statistics/
CONNECT
shiyuanzhang.com all rights reserved 2025 ©
Interested in collaborating, learning more about my work, or just want to chat? I'd love to hear from you. Feel free to reach out!